|
GenBank Report Data Extraction
We will first be selecting the nucleotide sequence located at the bottom of the Arabidopsis File.
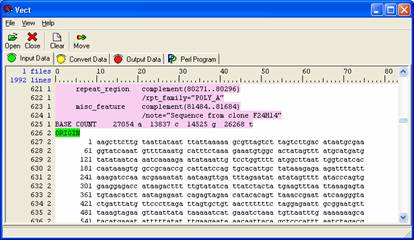
Right click on 'ORIGIN' located in field 0, line 626 and select New Block Open Condition from the pull down menu.
A green highlighted box will appear and the level from the origin will change because you open a new block.
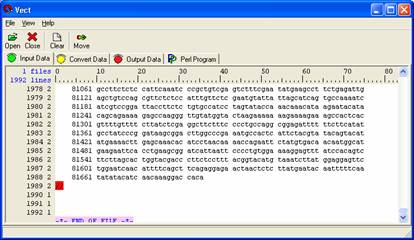
Scroll down to the bottom and right click on '//' located in field 0, line 1989, choose New Block Close Condition from the pull down menu.
A red highlighted box will appear and levels after ‘//” will change to 1 because you close new block.
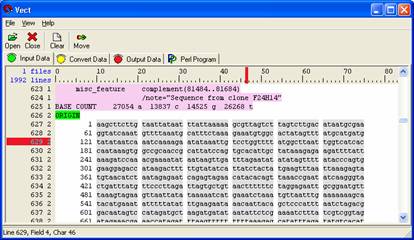
Left click on the first column containing the nucleotide sequence. This will highlight the entire column grey, meaning it is selected.
Then left click on the second column, then the third column, and so forth until you have selected all six of them. You are making a column selection and fields one through six should be highlighted in grey. The figure below shows the final appearance of the nucleotide sequence selections.
Note: If you do not have any grey highlighted regions in the 'Input Data' panel then you have not selected any data and no data can be moved over to the next panel.
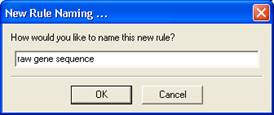
Select 'Move' from the icon panel and give your rule a descriptive name. Here you just to type “raw gene sequence” and press enter key to follow the remaining tutorial. This moves the data that you have selected to the 'Convert Data' panel where rule-dependent rules can be incorporated for better data extraction. (Rules are just a bunch of conditions you set so that you can extract data).
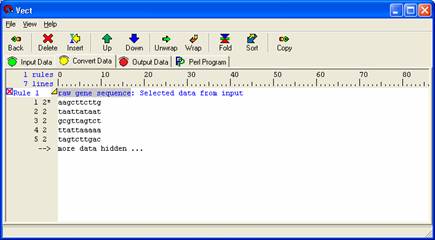
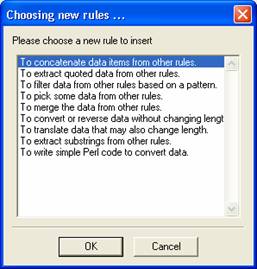
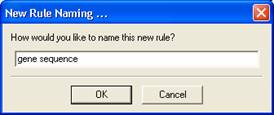
Select 'Insert' from the icon panel and select the Concatenation Rule. Give your rule a descriptive name. Here just type “gene sequence” for example,
 
|

